While Large Language Models (LLM) gain more and more traction, for recommendation systems, the effective way is still Large Embedding Model!
The term actually refers to one (or more) layer within a Deep Learning Recommendation Model whose primary responsibility is to map high-cardinality, sparse categorical input features (e.g., Ad IDs, domain, search query terms, feature hashes, LLM-generated artifacts) into low-dimensional, dense numerical vectors (embedding). This is typically implemented using massive embedding lookup tables, where each unique category value corresponds to a unique embedding vector. The term “Large” highlights the memory footprint and parameter count of these embedding tables, often dominating the overall model size due to the millions or billions of unique IDs/categories involved. These embedding vectors are trained jointly with the rest of the network to optimize the final recommendation task.
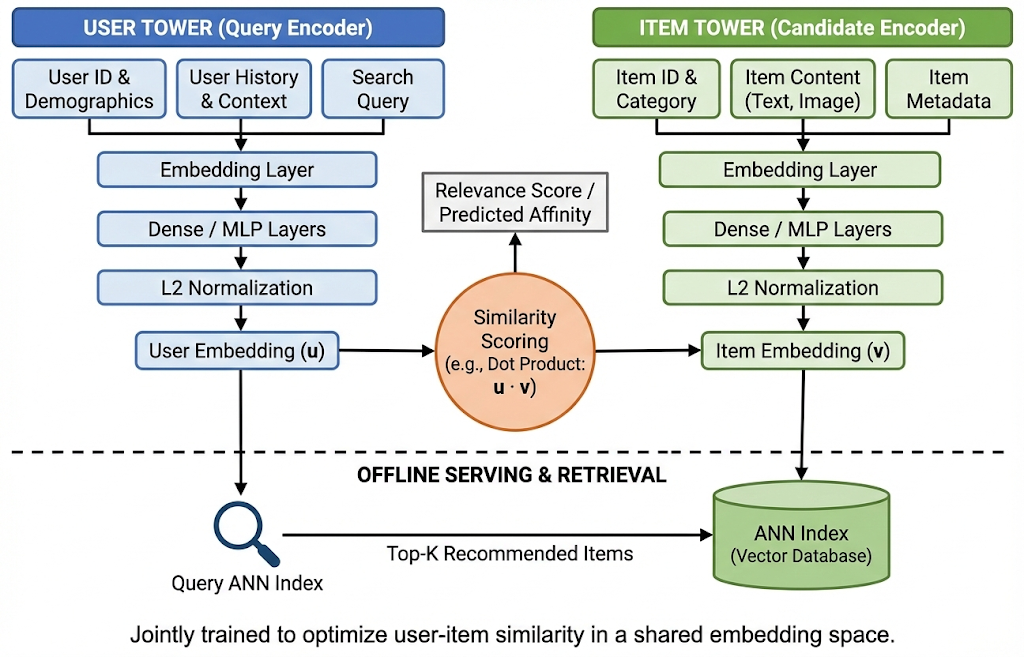 A quick illustration about two-tower architecture
A quick illustration about two-tower architecture
However, the future likely lies in convergence. Rather than replacing ID-based embeddings entirely, LLMs can be used to generate side-information embeddings (e.g., inferring user intent) which are then injected as dense features alongside the ID-based lookups. IMHO, that could be a great help for issues like cold-start.